

|
|

Speech timing problems associated with dysarthria often involve the presence of periods of extraneous silence and non-speech sounds as well as inappropriately timed or misplaced speech gestures. This study evaluated the performance of neural networks in detecting the presence of inappropriate or non-speech sounds and extraneous silence. A neural network program based on opt [E. Barnard and R. Cole. OGC Tech. Report No. CSE 89-014] which uses a conjugate gradient algorithm to adjust node weights was used to discriminate speech, non-speech, and silence in a reading of the rainbow passage by a single dysarthric Cerebral Palsy talker. Several methods of parameterizations of the speech signal were tried as input on several network architectures in order to find the optimal input configuration for training the network. In particular, two versions of DFT-based Bark Cepstral spectral parameterizations were compared to parameterization obtained with the PLP approach (Hermansky, 1990). Both of the DFT-based parameterizations slightly outperformed the PLP parameterization.
To determine what network configuration and speech parameterization method would best discriminate among silence, speech and non-speech segments in speech of a talker with dysarthria due to Cerebral Palsy.
A recording of the rainbow passage from a single male dysarthric speaker was labeled to identify regions of speech, silence, and non-speech vocalizations (e.g., loud breaths and other extraneous sounds) The silent regions were labeled automatically as any 25 msec or longer region of signal with fewer than 5 samples above a minimum amplitude threshold. The threshold value used for this study was 260 (out of a range of 32767). These automatically labeled regions were then manually checked for accuracy and consistency. Labeling of all other regions (speech and non-speech) was done manually with a waveform editor.
The waveforms were divided into 25 msec. windows with a step size of 10 msec. and parameterized using 3 different methods: Perceptual Linear Prediction (PLP), Spectrum Level Principal Components (SPLPC) with hi-pass filtering, and the cosine expansion of the auditory spectrum (ZCEP). The model order for each was chosen to result in 6 parameters/window. All parameters were then scaled to 2 standard deviations. (In the PLP method, all parameters but the gain were first multiplied by 100, to better match the magnitude of the gain coefficient.)
Neural network case widths of 5, 9, and 15 frames (30, 54, and 90 input nodes, respectively) were compared. The frame values were windowed using the Hamming windowing function. All input sizes were tested on networks with 9 hidden nodes and networks the the same number of hidden nodes as input frames.
To create the training and testing files, all cases were divided into their three classes, and the classes were then evenly divided into 6 parts in order to train on 5 and test on the sixth.
For each input-hidden node combination, 12 neural networks were run: The six class parts were rotated so that each part was used as a testing case in one network, and two initialization seeds were used for each network. The greatest test result for each of the 12 networks were averaged for the final analysis.
Finally, the effect of transition cases was studied by removeing them from both the training and testing lists, and then removeing them from just the training list. A case is considered a transition if it includes frames from different classes and the transition between classes is within two frames of the center frame.
Summary of variable factors in neural networks, and which were chosen to be manipulated in this study.
analysis frame: 25 msec
step size: 10 msec.
parameters per frame: 6
sample rate: 16000 samples/sec
neural network: back propogation with
Conjugant Gradient optimization
parameterization method PLP, SPLPC w/ hipass, ZCEP
input frames 5, 9, 15
input nodes 30, 54, 90
hidden nodes 5, 9, 15
neural network seed -1234, -200
transition cases train with -- test with,
train w/out -- test w/out,
train w/out -- test with
Break down of speech database:
68.7 seconds of Jim Fee speaking the Rainbow passage
Segment 25 msec.
Label Class windows % of total
Speech: none 1 5070 73.9%
Non-speech: 'N' 2 1145 16.7%
Silence: 'Q' 3 648 9.4%
total: 6863
| input width | 5 | 5 | 9 | 9 | 15 | 15 | percentage |
| trans cases | with | w/out | with | w/out | with | w/out | either |
| Speech | 5068 | 4788 | 5066 | 4786 | 5063 | 4783 | 78.5% |
| Non-speech | 1143 | 997 | 1141 | 995 | 1138 | 992 | 16.3% |
| Silence | 648 | 319 | 648 | 319 | 648 | 319 | 5.2% |
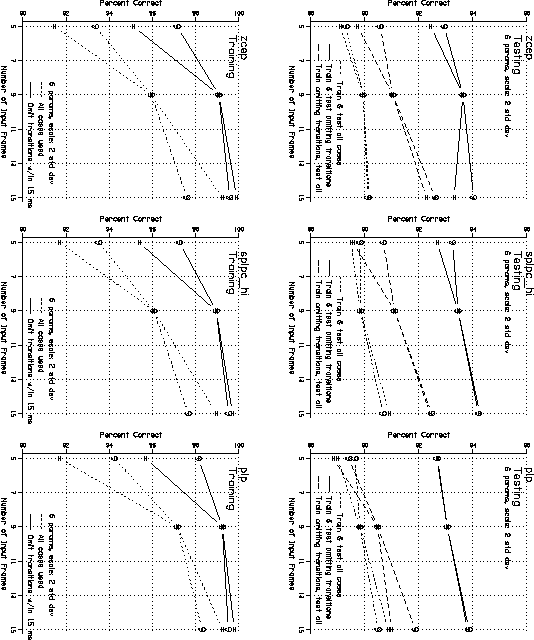
See graph - /vol/spl/src/opt/spch_nonspch/Plots/final.plt
SPLPC with hi-pass filtering produced the best results for all the network configurations, but not by a very large margin. Plp showed the worst results, but again not by much. In all cases, removing transitional regions from the training set consistantly improved the network results. Increasing the number of analysis frames also produced an improvement. However, at 15 input frames (90 nodes), increasing the number of hidden nodes from 9 to 15 either had no effect or a negative effect.
It is not surprising that all the neural networks performed better when transitional regions were removed from both training and testing sets. The classification of transitional frames is more ambiguous and therefore more likely to contain classification errors in both the training and testing data. However, it is somewhat surprising that networks trained without transitions performed consistantly better those trained with transitions when the testing set contained transitions. The normal expectation, of course, is for networks to perform best when the training data most nearly resemble the testing data. In the present case, it may be that the number of ambiguous transition cases is sufficiently large with respect to the number of "silence" cases that noise due to these cases overwhelms the network's ability to learn the silence classification. If this is true, the number of misclassified silence frames should be reduced when transitional segments are not included in the training data.
To examine this possibility further, confusion matrices for networks
trained with and without transition cases are presented in tables 5
and 6 respectively.

 Speech Home Page |
 ModelTalker |
ASEL Home Page |
|
Projects |
Publications |
Related Links |
Staff |
Facilities |
Upcoming Events |