![[MUSIIC]](images/mus.gif)

The primary objective of MUSIIC is the development of a multimodally controlled assistive robot for operation in an unstructured environment. The long term goal of the project is to have the assitive robotic arm attached to a wheel chair and allow the user the freedom from being limited to a fixed workcell.
The main philosophy of MUSIIC is based on the synergy between Humans and Machines. Inspite of our physical limitations, we excel in
Machines, on the other hand, excel in
We contend that by harnessing the best abilities of Human and Machine, can we arrive at an assistive robot that is feasible, usable and most importantly practical.
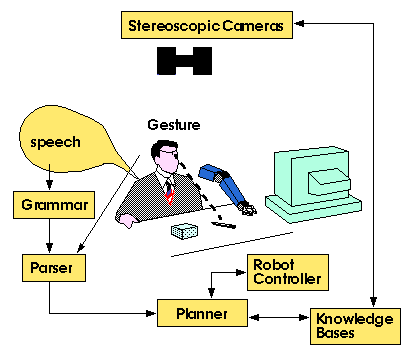
MUSIIC has four main components
A pair of cameras takes a stereoscopic snap-shot of the domain of interest and obtains information about the the shape, pose and location of objects in the domain.
The user instructs the robot arm by means of a multimodal interface which is a combination of speech and gesture. By gesture, we are currently focusing on deictic gesture, ie pointing gesture. This allows the identification of the user's focus of interest without having to perform the computationally difficult process of real-time object identification.
The speech input is a restricted subset of Natural Language [NL] and is called Pseudo Natural Language [PNL]. The basic grammar has the following structure:
Since this is a manipulative domain, the language struture is essentially, an action on an object to/at a location. As an example we may have inputs like:
A parser then generates the semantics of the user intentions from the combined speech and gesture input. The semantic interpretation of user input is then passed on to the planner.
The adaptive planner executes user intentions by generating the appropriate robot control commands. The adaptive planner reduces cognitive load on the user by taking over most high-level as well as all low level planning tasks. The planner is also able to adapt to changing situations and events, and either replans on its own or interacts with the user when it is unable to construct a plan on its own.
Underlying MUSIIC are a pair of knowledge bases. One is a knowledge base of actions, both primitive and complex, which is user extendible. The other is a knowledge base of objects, which contains information about objects in an abstraction hierarchy. The hierarchy has four tiers arranged on the basis of abstraction.
The knowledge bases allows the planner to not only make plans for manipulating objects about which it knows nothing a priori except what is obtained by the vision system, but also to make plans that are a more accurate interpretation of user intentions when more information is available from the knowledge bases.
A test-bed has been constructed to determine the validity of our proof of concept. The backbone computing machine for the vision interface is an SGI XS-24 IRIS Indigo computer. Pictures are taken by two CCD color cameras, model VCP-920 that have light-resolution 450 TV lines with 768X494 picture elements. Each camera is equipped with motorized TV zoom lens, model Computer M61212MSP. Cameras are connected to the SGI Galileo graphics board which provides up to three input channels. In this system we use two channels with s-video inputs. The Noesis Visilog-4 software package installed on the SGI machine is used as an image processing engine to assist developing the vision interface software. The speech system used is Dragon Dictate running on a PC. A six degree of freedom robot manipulator, Zebra ZERO, is employed as the manipulation device. The planner and knowledge bases reside on a Sun Sparc Station 5. Communication between the planner and the sub-systems are supported by the RPC (Remote Procedure Call) protocol.
![]()
![]()
![]()
Last Updated: June 15, 1996 Zunaid Kazi <kazi@asel.udel.edu>